Principal Component Analysis (PCA) is the classic linear approach to Dimensionality reduction. The intuition is easiest to see in two dimensions. Suppose we have a cloud of 2D points and we want to reduce it to 1D. The lazy thing to do is drop the coordinate, keep only . That works geometrically but loses information: the spread in is gone entirely. If the cloud has interesting variation in , we’ve thrown it away.
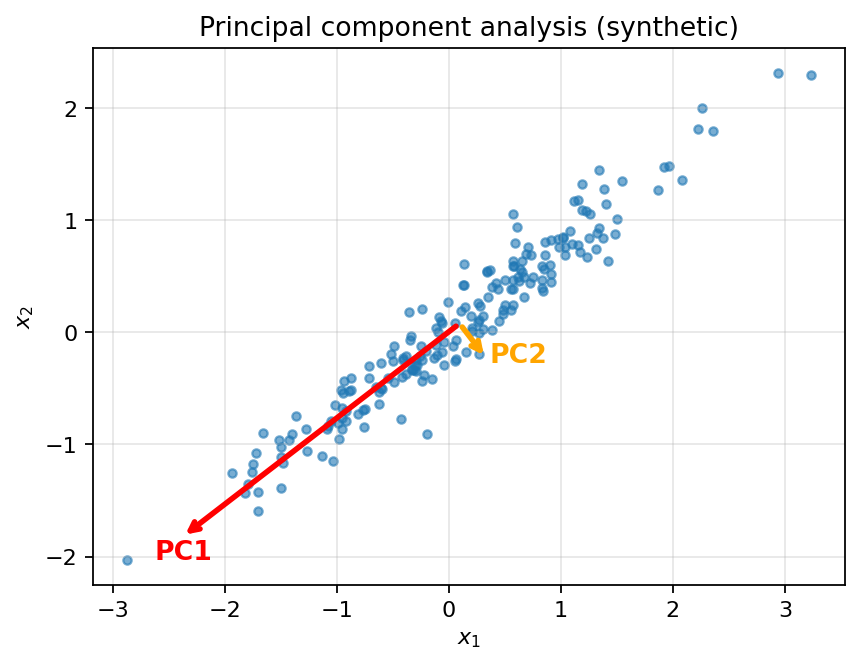 Principal components of a 2-D Gaussian cloud. PC1 captures the direction of greatest variance.
Principal components of a 2-D Gaussian cloud. PC1 captures the direction of greatest variance.
PCA does something smarter. Instead of projecting onto the or axis, it asks: is there some other line we could project onto that would preserve more of the variance? Often the answer is yes. If the cloud is elongated along a diagonal, projecting onto that diagonal preserves much more variance than projecting onto either of the original axes.
PCA finds the direction with the highest variance in the data; that’s the first principal component. It then finds the direction with the next-highest variance among directions orthogonal to the first; that’s the second principal component. And so on. Each principal component is a new coordinate axis, and the data, expressed in these new axes, has its variance concentrated in the first few components.
To reduce from dimensions to , keep the first principal components and discard the rest. If most of the variance is captured in the first few components, which is often the case in practice, the dropped components contained little variance, and the reduction is nearly lossless with respect to variance. The qualifier matters: PCA preserves variance, not “information” in general. If the meaningful distinction between classes lives along a low-variance direction (a small but important signal masked by a large but uninformative one), PCA will discard exactly the direction we care about. Variance is a useful proxy for information, not the same thing.
Before applying PCA, the data must be centered: every column shifted to have zero mean. Centering is mandatory; without it, the first principal component drifts toward the mean direction rather than the variance direction. When features are on different scales (a column in millimetres versus one in metres), they should also be standardized to unit variance (see Normalization), otherwise the high-magnitude column dominates and PCA gets misled by units rather than structure. StandardScaler in scikit-learn does both centering and standardization.
In Python with scikit-learn:
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
X = StandardScaler().fit_transform(X) # normalize
pca = PCA(n_components=2)
X_2d = pca.fit_transform(X) # N×2 arrayUnder the hood
The Introduction to Data Science textbook stops at the conceptual picture and library call. The mathematical machinery, usually left for a later machine-learning course, is worth a quick sketch.
For centered data ( rows, features), form the sample covariance matrix . This is a symmetric positive-semidefinite matrix. Its eigenvectors are the principal components: an orthonormal basis of in which is diagonal. The corresponding eigenvalues are the variances of the data along those directions. The first principal component (eigenvector with the largest eigenvalue) is the direction of maximum variance, that’s what makes it “principal.”
Equivalently, computed via SVD of the centered data: . The columns of are the principal components; the singular values relate to the eigenvalues by . This is how scikit-learn does it, since SVD is numerically more stable than forming explicitly.
The explained variance ratio of component is , the fraction of total variance captured by that component. Cumulative explained variance after keeping the top components is . A typical heuristic for choosing is to pick the smallest such that the cumulative ratio exceeds 0.9 or 0.95. In scikit-learn this is pca.explained_variance_ratio_.
PCA preserves global linear structure. t-SNE instead preserves local neighborhood structure and reveals cluster shapes that linear projections can miss. Running both on the same dataset and comparing the plots is informative: PCA tells you the shape of variance, t-SNE tells you the shape of neighborhoods.