Standard top-down design, applied at the assembly level where every detail matters. Going from a problem statement to working assembly: analyze, partition, choose data, organize modules, pseudocode, translate, test.
The steps:
- Analyze the problem. Understand the overall computing task end-to-end.
- Partition the problem into smaller, manageable subtasks.
- Characterize the data: what comes in as input, what goes out as output, what gets modified along the way.
- Select data structures (arrays, linked lists, stacks, etc.).
- Define and organize software modules that match the subtasks; specify the parameter passing between them.
- Refine in pseudocode. Describe the modules in pseudocode, working out the algorithm without worrying about syntax.
- Translate the pseudocode into the target assembly language.
- Generate executable code and test for correctness.
Why all these steps exist before you start writing assembly: assembly debugging is brutal. A typo in a register name doesn’t fail at compile time, it just produces wrong answers. Catching mistakes in pseudocode before translating saves enormous time.
Worked example
Problem: given a list of numbers, compute the average, then count how many values in the list are the average.
This splits into two subroutines:
CalcAvgtakes a list and its length, returns the average.CountGTorEQAvgtakes a list, length, and average, returns the count of elements average.
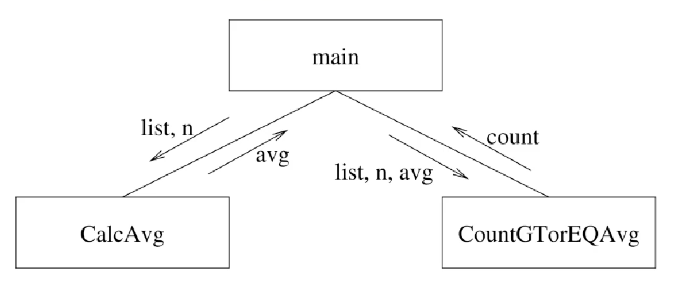
The main routine orchestrates: passes list, n to CalcAvg, gets avg back, then passes list, n, avg to CountGTorEQAvg and gets the count.
Below focuses on CountGTorEQAvg.
Pseudocode
CountGTorEQAvg(list, n, avg): // r4, r5, r6
count = 0 // r8
for i = 0 to n-1 do
if (list[i] >= avg) then
count = count + 1
end if
end for
return count // r2
The argument-to-register binding follows the Nios II ABI: list in r4, n in r5, avg in r6 (arguments go in r4–r7). The local count lives in r8. The return value goes in r2.
Assembly
CountGTorEQAvg:
subi sp, sp, 8
stw r8, 4(sp) # r8/r9 are caller-saved, saved here just to keep the example self-contained
stw r9, 0(sp)
movi r8, 0 # count = 0
ble r5, r0, count_done # n <= 0: skip the loop, never touch 0(r4)
count_loop:
ldw r9, 0(r4)
blt r9, r6, skip_inc # list[i] < avg, don't count it
addi r8, r8, 1
skip_inc:
addi r4, r4, 4 # next word
subi r5, r5, 1
bgt r5, r0, count_loop
count_done:
mov r2, r8
ldw r9, 0(sp)
ldw r8, 4(sp)
addi sp, sp, 8
ret
Things worth noticing
- ABI compliance. Inputs come in via r4–r7 (we use r4, r5, r6), the return value leaves via r2. r4–r7 are caller-saved, so we can clobber them freely; r8 and r9 are also caller-saved in the Nios II ABI but we still save them here to keep the example self-contained. This is the basic callee discipline.
- n=0 guard.
ble r5, r0, count_doneshort-circuits the loop whenn ≤ 0, so we never read0(r4)for an empty list. The original example ran the body once unconditionally and would fault onn=0, exactly the off-by-one pitfall below. - Inverted comparison for the if. “if list[i] >= avg” becomes
blt r9, r6, skip_inc: branch past the increment if the opposite condition holds. - Pointer increment by 4.
addi r4, r4, 4advances the list pointer by one word’s worth of bytes. - Result in r2, by the return-value convention.
- No
callto a sub-subroutine here. This is a leaf subroutine, so we don’t need to savera(the Link register). If we called another function inside, we would.
Why this took so much setup
The pseudocode is six lines. The assembly is twenty-five. Most of the difference is bookkeeping: stack frame, register saves/restores, manual loop arithmetic, explicit pointer manipulation. Every detail you’d take for granted in C has to be spelled out.
The design process front-loads the thinking before any of this bookkeeping happens. By the time you’re translating pseudocode to assembly, you’re not deciding what the code does, only how to express it. That separation is what makes assembly programming tractable.
Common pitfalls
Mistakes specific to assembly that the design process helps avoid.
Forgetting to save registers
Subroutines clobber registers. If you forget to save them on entry and restore on exit, the caller’s data is silently corrupted. The bug usually shows up far away from where it was caused: a value read after the call has changed unexpectedly.
The fix: enumerate every register your subroutine writes to in the pseudocode comments, then explicitly save/restore them. The discipline of caller-saved vs callee-saved convention exists exactly to make this mechanical.
Off-by-one in loop bounds
Pseudocode for i = 0 to n-1 is inclusive of but exclusive of . Assembly versions need to match. A common error: writing bgt r3, r0, loop (loop while ) when you meant bge r3, r0, loop (loop while ) or vice versa. Trace through with and to verify.
Pointer arithmetic mistakes
In assembly, advancing through an array of 32-bit words means addi r2, r2, 4, not addi r2, r2, 1. The pointer is a byte address, so incrementing by 1 advances one byte, not one element. Forgetting the multiplier is a frequent error.
For arrays of larger structs, the increment is sizeof(struct), not 4. Multiply by hand if needed.
Mixing up signed and unsigned comparisons
Nios II has both: bgt is signed, bgtu is unsigned. Mixing them up gives wrong answers when comparing values that interpret high bits as sign vs magnitude. Decide which signedness you want and use the matching branch consistently.
Stack pointer drift
If you subi sp, sp, 12 on entry but only restore addi sp, sp, 8 on exit, the stack pointer drifts up 4 bytes per call. After many calls, you’ve corrupted the caller’s stack frame. The save and restore sizes must match exactly.
Calling another subroutine without saving ra
A non-leaf subroutine that calls another subroutine must save ra (link register) before the call. The new call overwrites ra, and you’ve lost your return path. Result: the original return at the end of your function jumps to the wrong place — usually a crash, sometimes silent corruption.
Leaf subroutines (no internal calls) can skip this, since ra stays valid throughout.
Iterating on the design
Even with careful pseudocode, the first assembly translation rarely works perfectly. Typical workflow:
- Translate pseudocode line by line.
- Run on a simulator (or hardware).
- Compare actual outputs to expected.
- If wrong, single-step through to find the discrepancy.
- Fix, re-test.
Steps 4–5 often reveal an imprecise pseudocode line that translated to ambiguous assembly. Refine the pseudocode and retranslate.
The iteration tightens with experience. Eventually you write assembly that works on the first or second try, but the design process is what gets you there. New programmers should expect 3–10 iterations per non-trivial subroutine.
Beyond the example
The same nine-step process scales to multi-subroutine systems. For a system with 5 subroutines:
- Identify each subroutine and its responsibility.
- Define their interfaces (arguments and return values). This is the API.
- Define data flow: which subroutines call which, and what data passes between.
- Pseudocode each independently.
- Translate independently.
- Test each in isolation, then together.
Recursive top-down design, the same process you’d use in any language, with more low-level discipline at the bottom level.