A B-tree is a self-balancing search tree where each node holds many keys and has many children, not just two. It generalises the Binary search tree from “two children per node” to “up to children per node,” which keeps the tree shallow even for huge data sets. They’re what sits behind most database indexes and filesystem directories on disk.
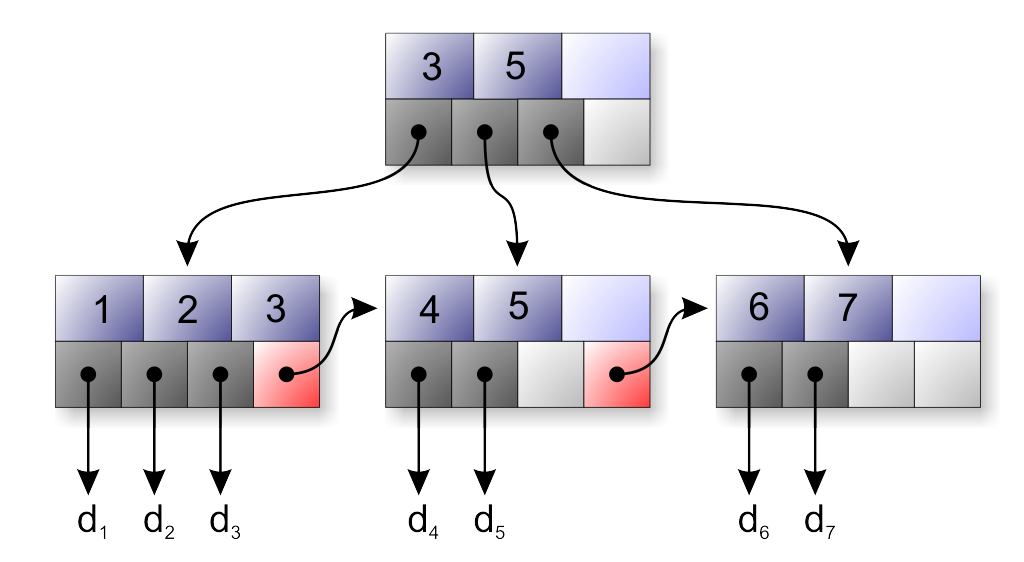 Image: Example B-tree, CC BY-SA 3.0
Image: Example B-tree, CC BY-SA 3.0
{kind=link}
The motivation is simple: a Red-black tree with keys is around 30 levels deep on average (worst-case — RB trees can be up to twice as tall as a perfectly balanced tree). That’s tens of random memory reads to find a key. On disk, where each read is a millisecond, that’s roughly 30 ms typical, up to 60 ms worst case. A B-tree of order 100 with the same number of keys is only levels deep — fewer than five reads. B-trees exist to minimise the number of node fetches, which matters whenever fetching a node is expensive (disk, network, cache miss).
Structure
A B-tree of order (the maximum number of children) satisfies:
- Every node holds between and keys (root may have as few as 1).
- A node with keys has exactly children.
- The keys in a node are sorted: .
- The subtree between and contains only keys in that interval. (Same ordering invariant as a BST, generalised.)
- All leaves are at the same depth.
Property 5 — every leaf at the same depth — is what keeps the tree balanced. Insertions and deletions enforce this by splitting and merging nodes, never by rotating.
Search
To find a key, walk down from the root. At each node, do a (binary or linear) search through the node’s keys to either find the key or pick the right child to descend into. The cost is comparisons across node fetches — the comparisons are cheap, the fetches are the expensive part.
Insertion
Always insert into a leaf:
- Search down to the leaf where the new key belongs.
- If the leaf has room ( keys), insert in sorted order. Done.
- Otherwise the leaf overflows. Split it: take the median key, push it up into the parent, and split the remaining keys into two new leaves.
- If pushing up makes the parent overflow, split the parent too. Recurse.
- If the root overflows, create a new root with one key — the only operation that increases the tree’s height.
Splitting is the symmetric counterpart of rotation in a BST: it’s the local fix that maintains the invariant.
Deletion
More fiddly than insertion. The cases:
- If the key is in a leaf and the leaf has more than the minimum number of keys, just remove it.
- If the key is in an internal node, replace it with its in-order successor (the smallest key in the subtree to its right), then delete the successor from its leaf.
- If a leaf would underflow (drop below keys):
- Borrow from a sibling that has more than the minimum (rotate one key through the parent).
- If no sibling can spare a key, merge with a sibling and pull the separator key down from the parent.
- Merging may underflow the parent — recurse upward. If the root ends up empty, the tree shrinks by one level.
B+ tree variant
Most databases use the B+ tree, a variant where:
- Internal nodes hold only keys (no data, just routing information).
- All actual data lives in the leaves.
- Leaves are linked into a sorted doubly-linked list.
The leaf list makes range queries fast: find the lower bound, then walk the list. SQL WHERE x BETWEEN a AND b is exactly this. Filesystem directory listings work the same way.
Why B-trees dominate disk storage
A disk read is roughly times slower than a memory access, so you want every disk read to do as much work as possible. A B-tree node is sized to fit a disk page (typically 4 KB or 8 KB), packing dozens or hundreds of keys per fetch. Fewer fetches per lookup means much faster queries.
Concrete examples:
- PostgreSQL, MySQL InnoDB, SQL Server: indexes are B+ trees.
- Linux ext4, NTFS, HFS+: directory indexes are B-trees.
- SQLite, BerkeleyDB: full database stored as a B-tree.
For an in-memory balanced search tree, see Red-black tree or AVL tree — those are the right choice when every “fetch” is just a pointer dereference. B-trees are specifically for the case where fetches are expensive.