The learning rate is the size of each step in Gradient descent: how far we move along the negative gradient before recomputing it. Conventionally written (the Greek letter eta), it’s one of the main hyperparameters in training a machine-learning model.
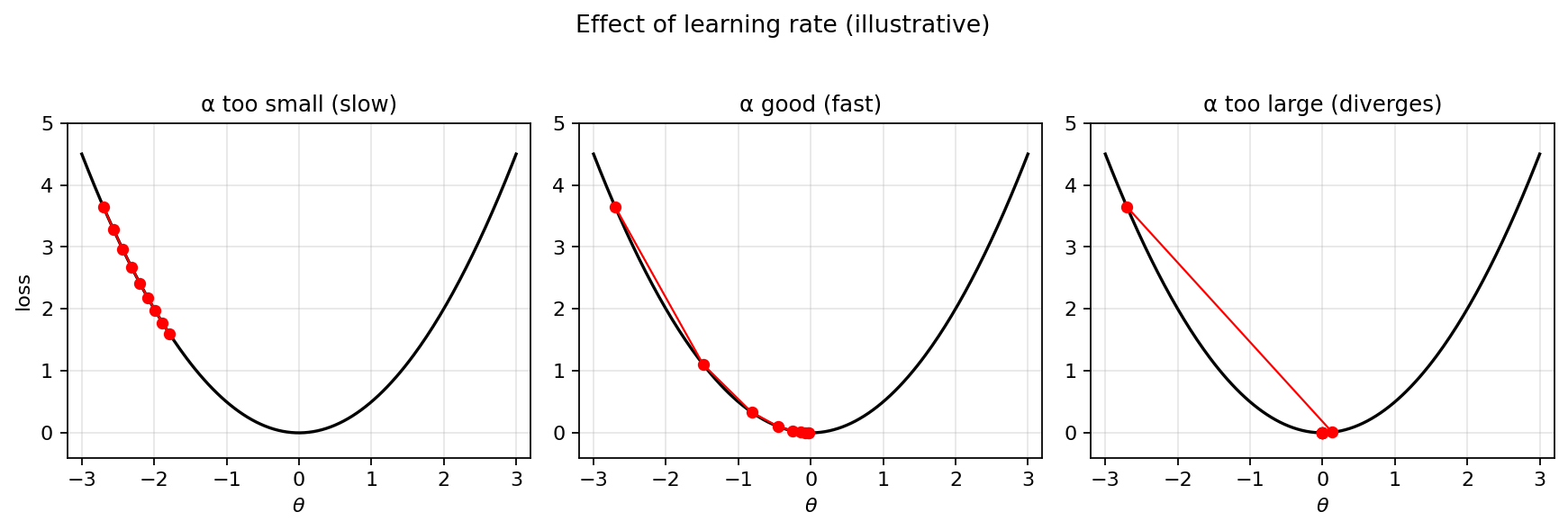 Effect of learning rate on convergence. Too small → slow; about right → fast; too large → oscillation/divergence.
Effect of learning rate on convergence. Too small → slow; about right → fast; too large → oscillation/divergence.
The update rule for gradient descent:
The negative gradient says which direction decreases the loss. The learning rate says how far to step in that direction.
Too small
If is too small, training is very slow: we creep down the hill in tiny steps and need many iterations to reach the minimum. With , an optimizer that would converge in 100 steps at might take 100,000 steps. The loss curve is smooth but flat, barely decreasing over many iterations.
Too large
If is too large, the updates may overshoot the minimum. We compute the gradient at the current point, take a big step in that direction, and end up on the other side of the valley, possibly at a point with higher loss than where we started. The loss may oscillate, bounce around without settling, or diverge entirely with the parameters growing without bound.
Just right
A good learning rate produces a loss curve that drops quickly at first, then levels off as it approaches the minimum. The descent should be steady — neither glacial nor spasmodic.
Picking it
Picking is partly an art. Common starting values are 0.01 or 0.001. Run training for a while, look at how the loss changes, adjust:
- If the loss drops quickly and smoothly, is roughly right.
- If the loss stays flat, is too small — increase by 10×.
- If the loss bounces around or grows, is too large — decrease by 10×.
A worked example from the textbook: minimizing starting from . With , the iterations converge to the analytical minimum in about 25 steps. With , the path overshoots, taking large steps past the minimum, then correcting back. With much larger, the path spirals outward and diverges. With , the path creeps slowly inward and doesn’t reach the minimum within 200 iterations.
Beyond a constant
Modern training algorithms often use a learning-rate schedule, an that varies over time. Common patterns:
- Step decay: drop by a factor of 10 every epochs.
- Cosine annealing: follows a cosine curve from to .
- Warmup: start small, ramp up linearly to , then decay.
These help training converge faster early (when far from the minimum, big steps help) and more precisely later (when near the minimum, small steps prevent overshoot).
Adaptive methods like Adam, RMSProp, and AdaGrad adjust the learning rate per parameter based on the history of gradients, removing some of the need to tune by hand.